Voor meer dan 99% van de bevolking zijn machine learning algoritmes een ‘black box’. Maar is dat wel echt zo? Ik denk dat visualisaties kunnen helpen om beter begrip te krijgen van de werking van algoritmes. In deze blog neem ik je mee in mijn top 5 van visualisaties die mij helpen om onder de motorkap van een algoritme te kijken, want iedereen kent de uitdrukking: ‘een beeld zegt meer dan duizend woorden’.
Om deze top 5 te illustreren, borduur ik verder op de casus die ik in mijn vorige blog heb beschreven, waarin een fictieve gemeente probeert te voorspellen welke burgers al dan niet in de schuldhulpverlening dreigen te komen.
Op nummer 5: Hoe goed voorspelt het algoritme wie in de schuldhulpverlening terecht dreigt te komen?
De eerste visualisatie is de zogenaamde Confusion Matrix waarin wie daadwerkelijk wel of niet in de schuldhulpverlening terecht komt (‘True label’) wordt afgezet tegen de voorspelling van wie in de schuldhulpverlening terecht komt (‘Predicted label’). Een 0 betekent geen schulhulpverlening en een 1 betekent wel schuldhulpverlening. Door deze eenvoudige tabel krijg je goed inzicht op de prestatie van het gebruikte algoritme (in dit geval een Random Forest en een uitleg over de werking hiervan lees je in mijn vorige blog).
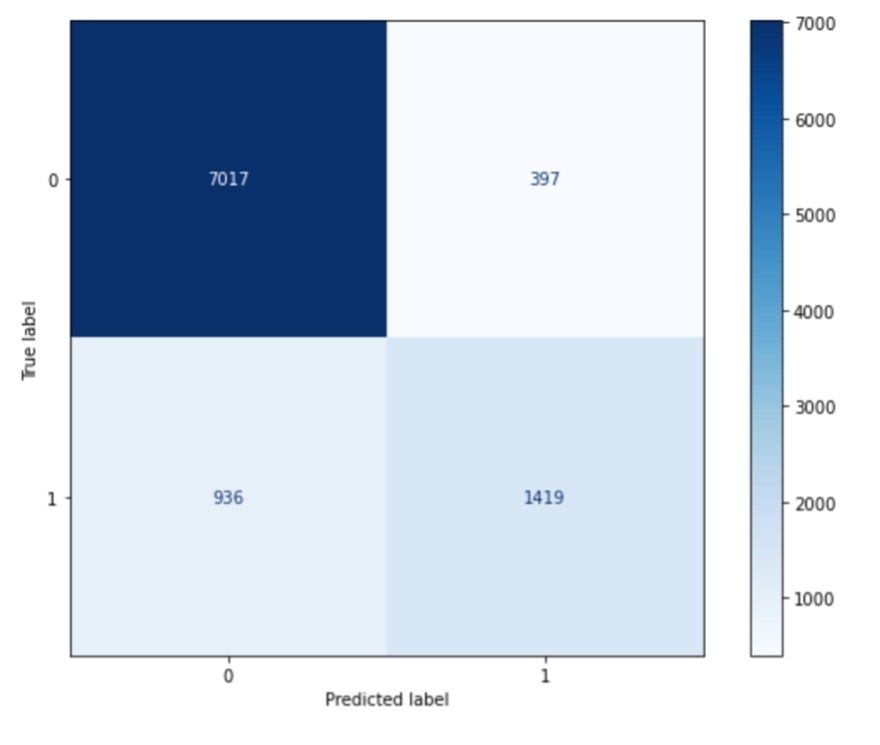
Figuur 1: Confusion Matrix
Het algoritme voorspelt correct wanneer de enen en de nullen overeenkomen en dat geldt voor 8.436 burgers (7.017 + 1.419). Wat overblijft, zijn de valse negatieven (936 burgers) en valse positieven (397 burgers). Dit betekent dat het algoritme voor 936 burgers niet voorspelt dat zij in de schuldhulpverlening komen, maar dat in de werkelijkheid wel zijn gekomen. En andersom: het algoritme voorspelt voor 397 burgers dat zij in de schuldhulpverlening komen, terwijl dat niet het geval is.
Op basis van de Confusion Matrix kunnen we gemakkelijk de accuraatheid van het algoritme uitrekenen, want dat zijn alle correcte voorspellingen gedeeld door het totaal aantal. We komen dan op een accuraatheid 86% (8.436 gedeeld door 9.769).
Op nummer 4: Hoe goed voorspelt mijn algoritme voor mijn hele dataset?
Het komt geregeld voor dat het algoritme beter voorspelt voor de ene fractie van de dataset dan voor de anderen. Om erachter te komen in hoeverre dit ook daadwerkelijk het geval is voor jouw dataset, kan je onderstaande visualisatie gebruiken.
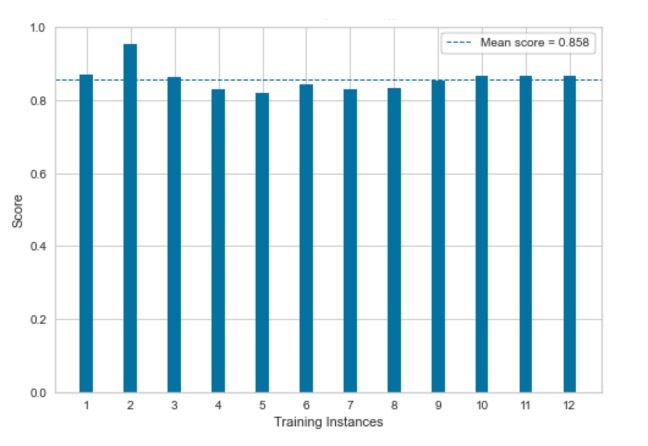
Figuur 2: Crossvalidatie
De techniek in dit voorbeeld is dat de dataset willekeurig wordt opgedeeld in twaalf gelijke delen en voor elk ééntwaalfde fractie wordt uitgerekend hoe goed het algoritme voorspelt. In figuur 2 zie je hiervan het resultaat en het valt op dat het algoritme niet voor elke fractie evengoed voorspelt. Ook geeft de visualsatie de gemiddelde accuraatheid van deze zogenaamde crossvalidatie weer en die komt overeen met de accuraatheidsscore uit de Confusion Matrix.
Als er per fractie enorme verschillen zijn, is het goed om te kijken naar de datakwaliteit, de hoeveelheid data en het aantal variabelen dat je tot je beschikking hebt.
Op nummer 3: Hoe hangen de onderliggende variabelen in het algoritme met elkaar samen?
Eén van de zaken die bepalend is hoe goed je algoritme is, is de onderlinge samenhang van alle variabelen. Dat is de zogenaamde correlatiematrix en in figuur 3 zie je hiervan een voorbeeld:
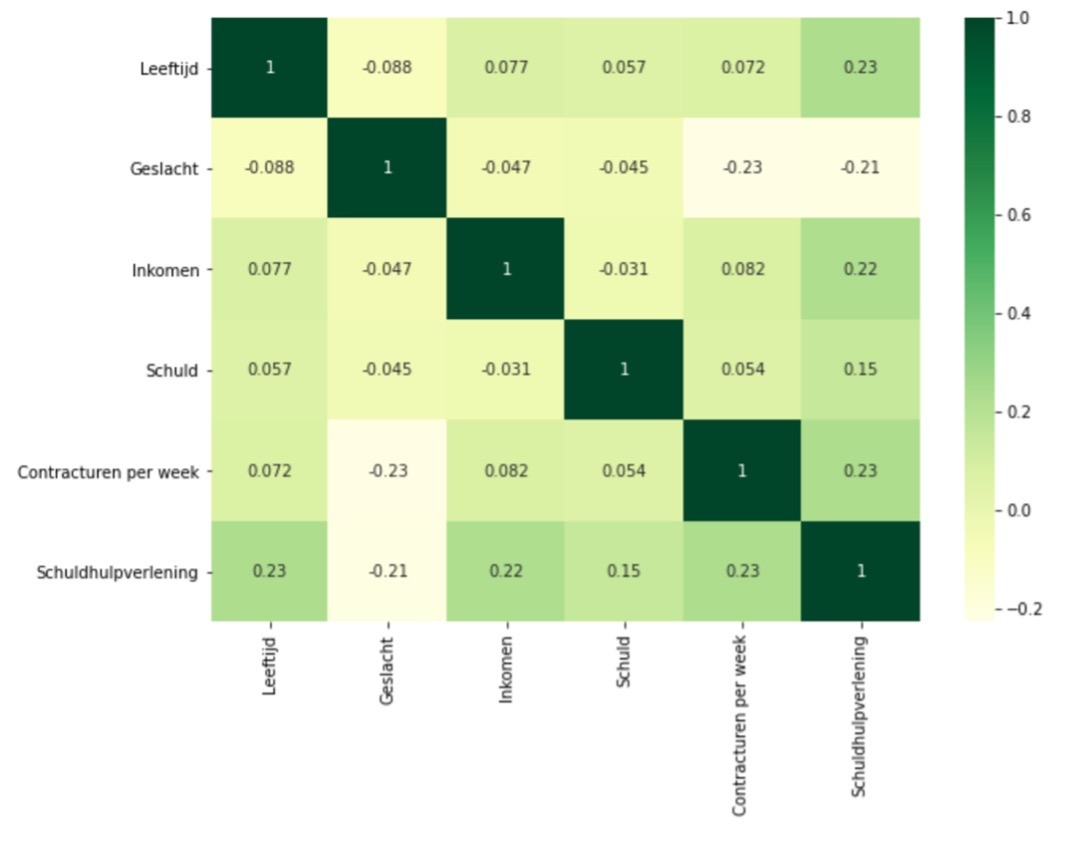
Figuur 3: Correlatiematrix
Het is belangrijk om erop te letten welke voorspellers sterk met elkaar samen. Als ze te sterk met elkaar samenhangen – zeg een correlatie boven de 0.6 – is het het overwegen waard om één van beiden te kiezen. In dit voorbeeld kunnen alle variabelen op basis van de correlatiescores geselecteerd worden in het uiteindelijke algoritme, omdat deze scores vrij laag liggen (tussen de -.23 en .23).
Op nummer 2: Hoe kan ik mijn algoritme optimaliseren, zodat hij beter presteert?
Veel algoritmes hebben verschillende knoppen waaraan gedraaid kan worden. In ons voorbeeld gaat het knopje ‘max depth’ over hoe complex het Random Forest algoritme uiteindelijk moet worden.
Onderstaande visualisatie is een hulpmiddel om het algoritme te optimaliseren door in dit geval de waarde van de ‘max depth’ te variëren.
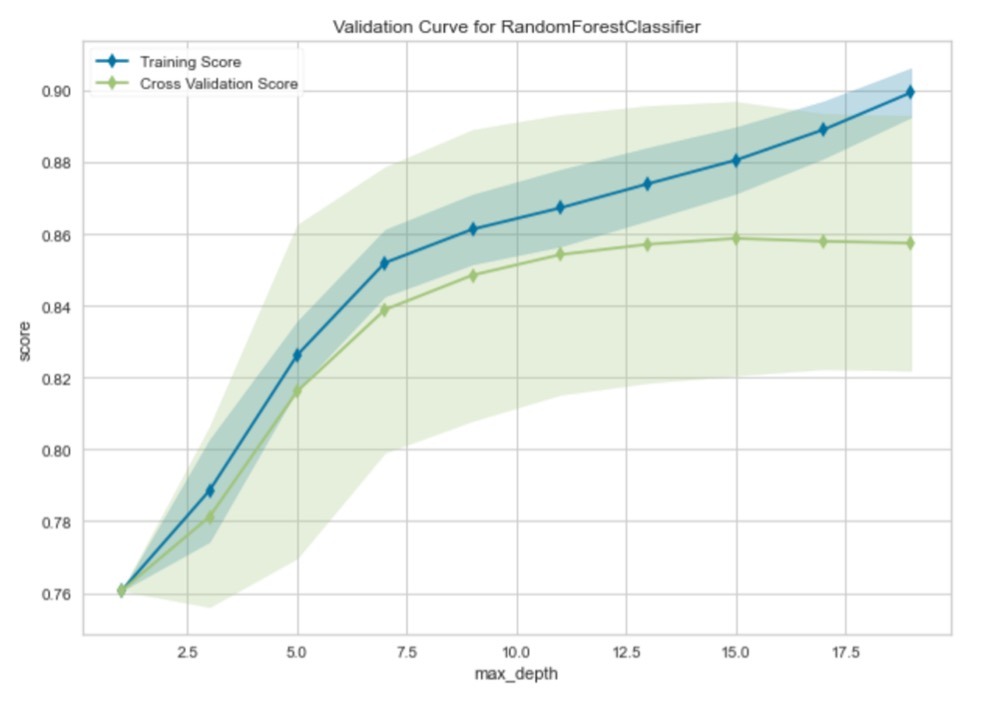
Figuur 4: Validatiecurve
De blauwe lijn gaat over het effect van dit knopje op de data die het algoritme tot haar beschikking heeft en je ziet hoe complexer het Random Forest hoe beter hij wordt.
De groene lijn laat zien hoe goed het getrainde algoritme zich laat generaliseren naar data die het nog niet gezien heeft. Het optimum ligt vaak vlak voordat de crossvalidatiescore afvlakt. In andere woorden, door meer detail en complexiteit toe te voegen aan het algoritme wordt het moeilijker om te voorspellen voor ongeziene observaties vanaf diepte 15. In dit voorbeeld lijkt het optimum dus te liggen op een maximale diepte van 15. Door het algoritme hierop in te stellen, is de verwachting dat het algoritme beter presteert om te voorspellen of burgers in de schuldhulpverlening gaan komen.
Op nummer 1: Wat is het belangrijkst voor de uitkomst van mijn algoritme?
Een relevante vraag is natuurlijk: aan welke variabelen hecht het algoritme meer of minder waarde? De volgende visualisatie geeft antwoord op deze vraag. In dit algoritme worden 108 variabelen meegewogen. Hieronder worden de 8 belangrijkste weergegeven.
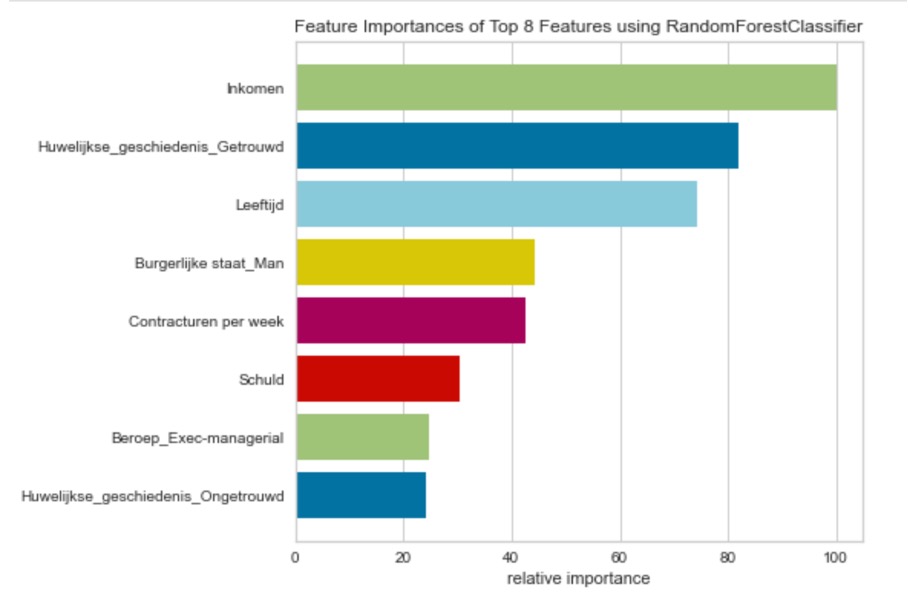
Figuur 5: Belangrijkheid van voorspellers
Dit geeft een idee wat het algoritme meer of minder belangrijk vindt. In dit voorbeeld heeft het inkomen van burgers de meeste impact op de uitkomst. Deze visualisatie is weer een puzzelstukje om de werking van het algoritme verder te ontrafelen.
In dit artikel heb ik mijn top 5 van visualisaties op een rij gezet die mijn inziens onmisbaar zijn om te kunnen vertrouwen op je machine learning algoritme. Deze vijf visualisaties gebruik ik zelf áltijd. Er zijn nog veel meer interessante visualisaties die het inzicht kunnen vergroten. Meer weten over hoe je door middel van visualisaties meer begrip van je algoritmes kunt krijgen? Neem contact met me op via stefan.deblij@vka.nl. Samen kunnen we kijken hoe we met goede visualisaties de kwaliteit van machine learning algoritme(s) kunnen verbeteren.
Bronnen
- https://scikit-learn.org/stable/
- https://www.scikit-yb.org/en/latest/
- Guido, S. & Müller, A.C. (2017). Introduction to Machine Learning with Python: A guide for Data Scientists. O’Reilly.